emotive asl
Emotive Audio; Increasing Expressivity of Text-to-Speech through Facial Emotion Recognition from Videos
Working on a paper, not releasing the technical details just yet. I aim to publish soon! If you want to discuss the math and code with me, please contact me! Collaborating with Rhea Mitr and Priti Rangnekar.
Preface and Inspiration
This is probably one the most massive codebases I’ve built or worked on. It’s not public yet, for obvious reasons, but I’ll try to provide some high level insights here of the different components that make up this project.
Overview
In this research, we explored using a transformer model to generate realistic audio that matches emotional expressions from facial images and text inputs. Our dataset, sourced from YouTube videos, was preprocessed to extract 48x48 facial images and corresponding text inputs. We trained an emotion detector inspired from a VGG-19 model for facial expressions and a pretrained BERT text-embedder to encode textual data, integrating these into an multi-modal attention model to generate waveform outputs based on combined text and emotion inputs. Our objective was to generate waveforms consistent with the input text and emotion described in the input facial expressions. Using a multi-component loss function with terms for mean squared error, spectral differences, signal-to-noise ratio, and energy penalizations, we aimed to balance performance metrics. Results showed that higher encoding and decoding lengths significantly improved waveform stability and noise reduction. Models that didn’t explicitly penalize noisy outputs produced more realistic-sounding audio, consistent with the input emotion and reference waveform. This study concludes that increasing data resolution and exploring more sophisticated loss functions could further enhance model performance. Future work will focus on expanding the dataset, refining loss terms, and improving data resolution to better capture the complex relationships between facial expressions and emotions, enhancing the realism of the generated audio.
Objective
Trying to extract emotion from such facial expressions and sign language symbols into audio that conveys the emotion of the ASL speaker.
Stage 1 – Getting the Data
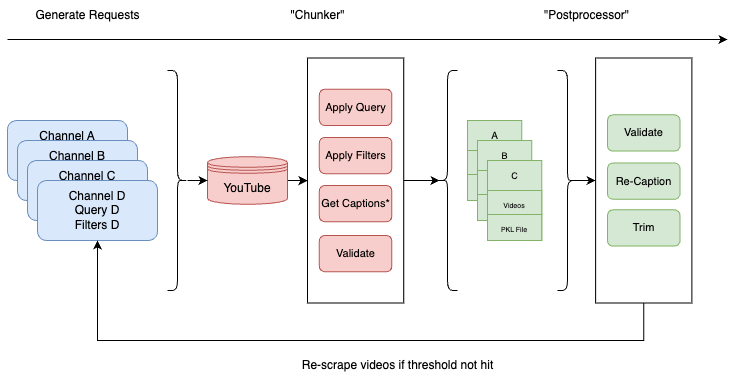
Figure 1: The steps taken to autonomously scrape high-quality video + transcriptions from YouTube given search parameters.
Data, data, data. There’s no large dataset out there that has all three requirements for training our models: ASL, associated transcript, corresponding audio, and facial expression (please email me if you know one, I will be indebted to you haha). So, I made a package that systematically (and quickly) downloads videos that match your natural language search parameters (eg. “ASL Sign Language Videos”) to your local disk. We ended up collecting over 1230 GB worth of videos this way (stay tuned, I might post it on pip if there’s enough interest from people). In reality, we actually only need two things – corresponding audio and facial expressions – to train our model; there might (not to my knowledge, please email me if you know of one) be some dataset that just has … videos of people (we can just a transcription model to get the associated transcript from the audio). I’ve always wanted to use YouTube for this since it’s so rich with data, hence this package.
Stage 2 – Training Submodules
Couple different core submodules: I wrote a transcription package + face segmentation package as well to get transcripts from audio for YouTube video that didn’t have good transcripts + get the faces of people in videos, respectively. There’s nothing really all that ground-breaking in this stage, since it’s just stringing together existing APIs and making wrappers for them. There’s quite a bit of implementational detail I won’t get into here, but one could say there was some novelty and serious design decisions I had to make when synchronizing chunks of audio, segmented video frames, and the associated transcript. These decision decisions came to have a pretty crucial impact on data efficiency 1) the amount of the data ultimately carrying-forward from the initial 1.23TB of data for training 2) the quality of the data (consider situations when parts of videos don’t have faces or audio).
Anywho, here are a tid-bit of what some of the data looks like.
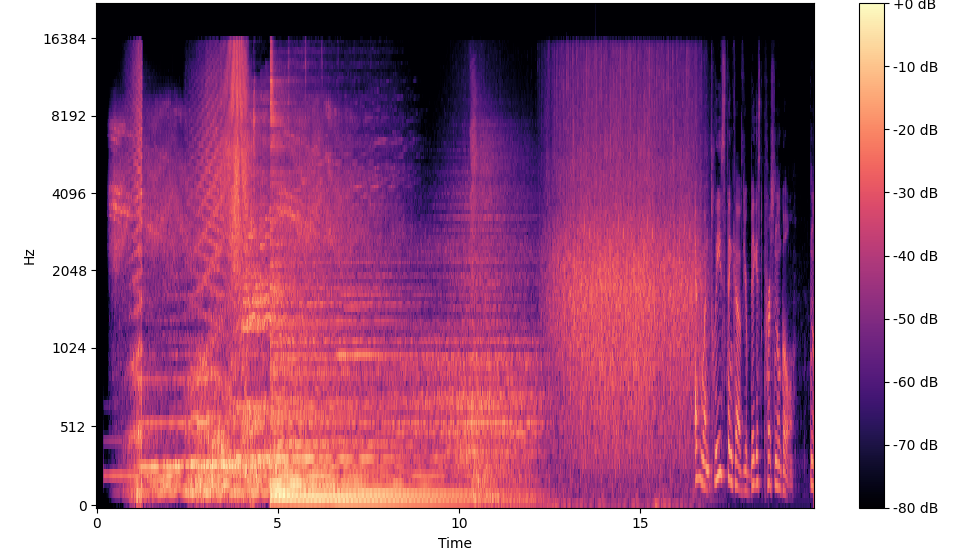
Figure 2: A spectrogram of an entire video from the training dataset. Due to not the entire 15-seconds consisting of facial expressions, and even if it did, memory contraints, the 15-second segment was split into "chunks."
Stage 3 – Training the Emotive Text-to-Speech Model
Of course, we need a baseline. We use Suno AI’s Bark for TTS.
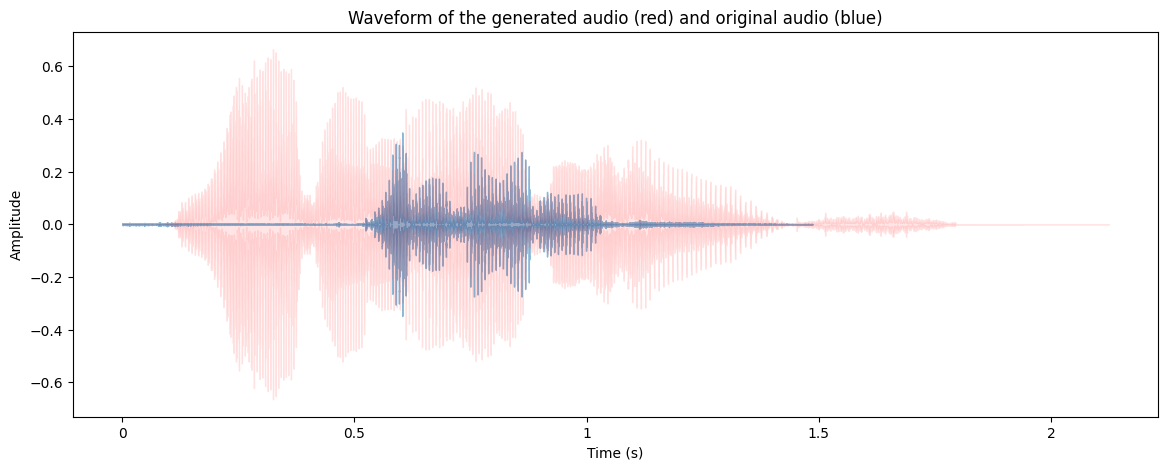
Figure 3: Two overlayed waveforms. The blue one is from Suno and the red one is the ground truth audio from YouTube.
There were a series of metrics we defined (eg. signal-to-noise ratio, Dynamic Time Warping, etc.) we used to compare two arbitrary waveforms against one-another. Sometimes, these metrics also doubled as loss components in the training process.
The final model that we built was an encoder-decoder transformer (plus some additional auxiliary convolutional/tokenizer/tokenizer models) that accepts a .mp4 file chunk and ground truth audio for that chunk and outputs a waveform. It compares the output waveform to the ground truth audio, which is utilized in the loss function calculation. I know what you’re thinking (maybe): generating a waveform isn’t the brightest idea. You’re right: we actually tried generating a mel-spectrogram and integrate a separate Vocoder that decodes the mel-spectrogram to output audio since that is more dense and so makes it easier for the model to learn. Unfortunately, we ran into issues working with the spectrogram in the transformer and “Vocode-ing,” so we decided to work with a sample \(1 \times T\) tensor reference waveform input and output, where \(T\) is controlled by the encoder-decoder maximum sequence lengths we set.
Anyways, we are at a point where the model is learning (loss functions and validation metrics are going down) on paper, but don’t seem to output waveforms that reflect exactly how much it’s learned. I like to say that the model is shy right now, and still has learn how to get out of its comfort zone and make some noise.
Welp. Out of the 15 or so plots I have monitoring the training process on Wandb, here’s a pretty cool one!
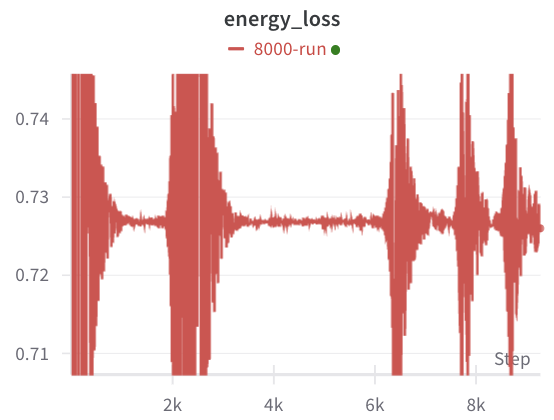
Figure 4: The energy loss oscillates over time. This is just something that's inversely proportional to the energy (kind of like how noisy/loud the signal is on average).
The training began with a relatively high energy loss, showing that the underlying energy of the generated signal was quite low. This makes sense, since early on in the training process, the transformer does not generate a coherent audio signal with distinguishable frequency components. As time passes, we notice that the energy interestingly does continue to oscillate over time, but for shorter and shorter intervals. This indicates that the underlying waveforms generated by the transformer became progressively more stable. This is, the transformer is producing higher energy signals over time – to match the underlying higher-energy reference waveform – and only occassionally generate silent outputs, and when they do, for shorter periods of time. This is one possible interpretation, but of course, I could totally be deluding myself – more analysis has to be done.
Stage 4 – Integrating in ASL
This is the big next component of the project that will really tie things together. If you’ve read this fair into this aimless blog of sorts and are interested in working on this module with me and perhaps even have background in translating ASL to text, definitely shoot me an email!