CodeSage
A generative framework mapping "good" code to "bad" code
The full paper can be found here.
Collaborated with Michael Nath and Joseph Tey.
Abstract
We propose a novel system, CodeSage: a generalizable method to generate higherquality code snippets. While most studies focus on specialized models for code quality improvement tasks, such as fixing bugs, the uniqueness of CodeSage lies in using a Github reputation score to evaluate the quality of our functions. We break our task into three main contributions: 1) aggregate clusters of code functions where each cluster represents one specific intent category; 2) within each cluster, score the quality of each function using a unique Github reputation score and designate the top ones as high quality code snippets of that intent category; 3) aggregate a dataset mapping low-quality functions to corresponding high-quality; and 4) fine-tune a pre-trained Seq2Seq transformer model that generates a high-quality code function given low-quality code. Our main contributions include offering a generalizable and dynamic way to identify “intent” behind code snippets, publishing a dataset for the public annotated with reputation scores, and confirming robustness of our final Seq-2-Seq model through comparative analysis with silhouette scores.
High-Level Approach
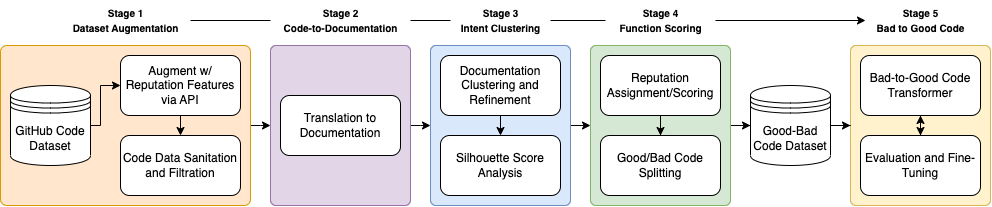
An overview of the different stages in our approach. We begin with a GitHub Code Dataset of 10K Python functions, where for each function, we calculate a reputation score and filter out any code snippets that are improper. Then we use a large-language model (LLM) such as GPT to retrieve documentation for every piece of code. Then, we cluster the code snippets into various intent categories based on the documentation for each snippet. For each cluster, we split it into “bad” and “good” code according to some heuristic and make mappings of “bad” to “good” code: this composes a training dataset. This dataset is used to train a transformer (finetuning a Code-T5 model) and evaluating the performance.
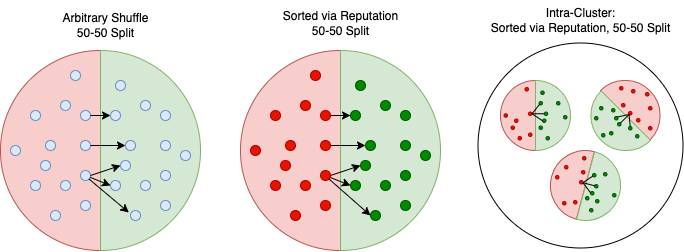
This figure shows the three different methods to segregate good and bad code considered to solve the greater objective of generating good code from bad code. The smallest circles represent a code snippet including its associated documentation. The arrows connecting the red-area circles to green-area circles represents the pairwise construction of our dataset for our final code-to-code model – as mentioned earlier. The left and middle arrangements represent the two baseline avenues discussed below, where the former involves randomly assigning half the functions to be bad code. The latter involves ranking based on a reputation score from least to greatest and assigning the first half to be bad code. The right-most figure is an outline of the CodeSage architecture, where code snippets are first clustered as per their documentation, subsequently assigned a reputation score, and then split in half