better egos 🚧
Self-Driving and Self-Flattering; Crafting a World that Amplifies Your Ego
Was previously working on a paper, not releasing the technical details just yet. Perhaps publishing. If you want to discuss the math and code with me, please contact me! Collaborating with Kanghoon Lee, Jiachen Li, and David Isele, in collaboration with the Honda Research Institute.
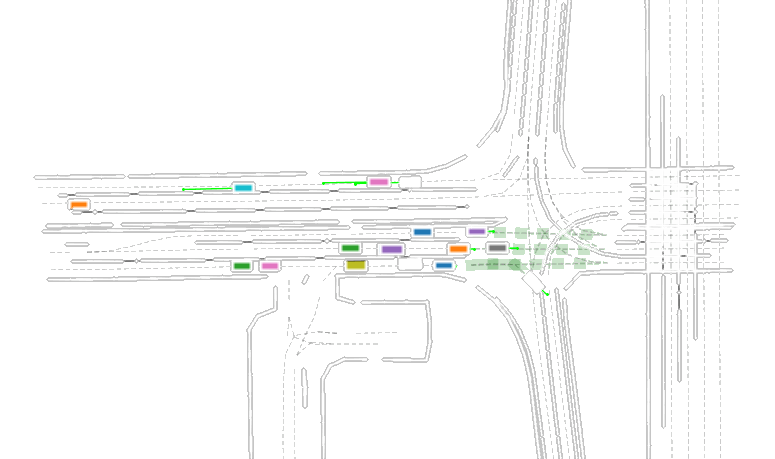
Replay of a single scene from an AV dataset containing real-life vehicle trajectory recordings. An ego vehicle is set (eg. center orange) and surrounding social trajectories are perturbed (a single frame from a particular scenario sourced from the Waymo Motion Dataset).
But here’s the something quick in-case you’re really wondering.
Introduction
Reinforcement learning has proven to be a useful paradigm to au- tonomously train a car (known as an ego vehicle) how to drive. However, such vehicles often collide with other vehicles on the road (known as social vehicles) due to an inability to generalize to unseen situations. Unstable ego policies can result in dangerous scenarios. In short ego policies struggle to handle out-of-distribution traffic scenarios (such as complex social vehicle interactions it has never encountered before). Hence, it is of absolute importance to the diversity of data an ego vehicle experiences during train-time to avoid sub-optimal performance in test-time.
Objective
Train an ego vehicle in such a way that it is able to robustly and reasonably handle out-of-distribution scenarios. More specifically, discover a way to systematically introduce di- versity in the ego training process without sacrificing perfor- mance (eg. number of collisions).
🚧 still working on this page (come back later) 🚧