worldview
Enabling convenient access to diversity of perspectives around the world.
🏆 TreeHacks 2022 – Winner (VMWare) Collaboration Award. Collaborated with Michael Nath and Joseph Tey. From the DevPost.
Overview of our project.
Inspiration
The three of us believe that our worldview comes from what we read. Online news articles serve to be that engine, and for something so crucial as learning about current events, an all-encompassing worldview is not so accessible. Those new to politics and just entering the discourse may perceive an extreme partisan view on a breaking news to be the party’s general take; On the flip side, those with entrenched radicalized views miss out on having productive conversations. Information is meant to be shared, perspectives from journals, big, and small, should be heard.

What it does
WorldView is a Google Chrome extension that activates whenever someone is on a news article. The extension describes the overall sentiment of the article, describes “clusters” of other articles discussing the topic of interest, and provides a summary of each article. A similarity/dissimilarity score is displayed between pairs of articles so readers can read content with a different focus.
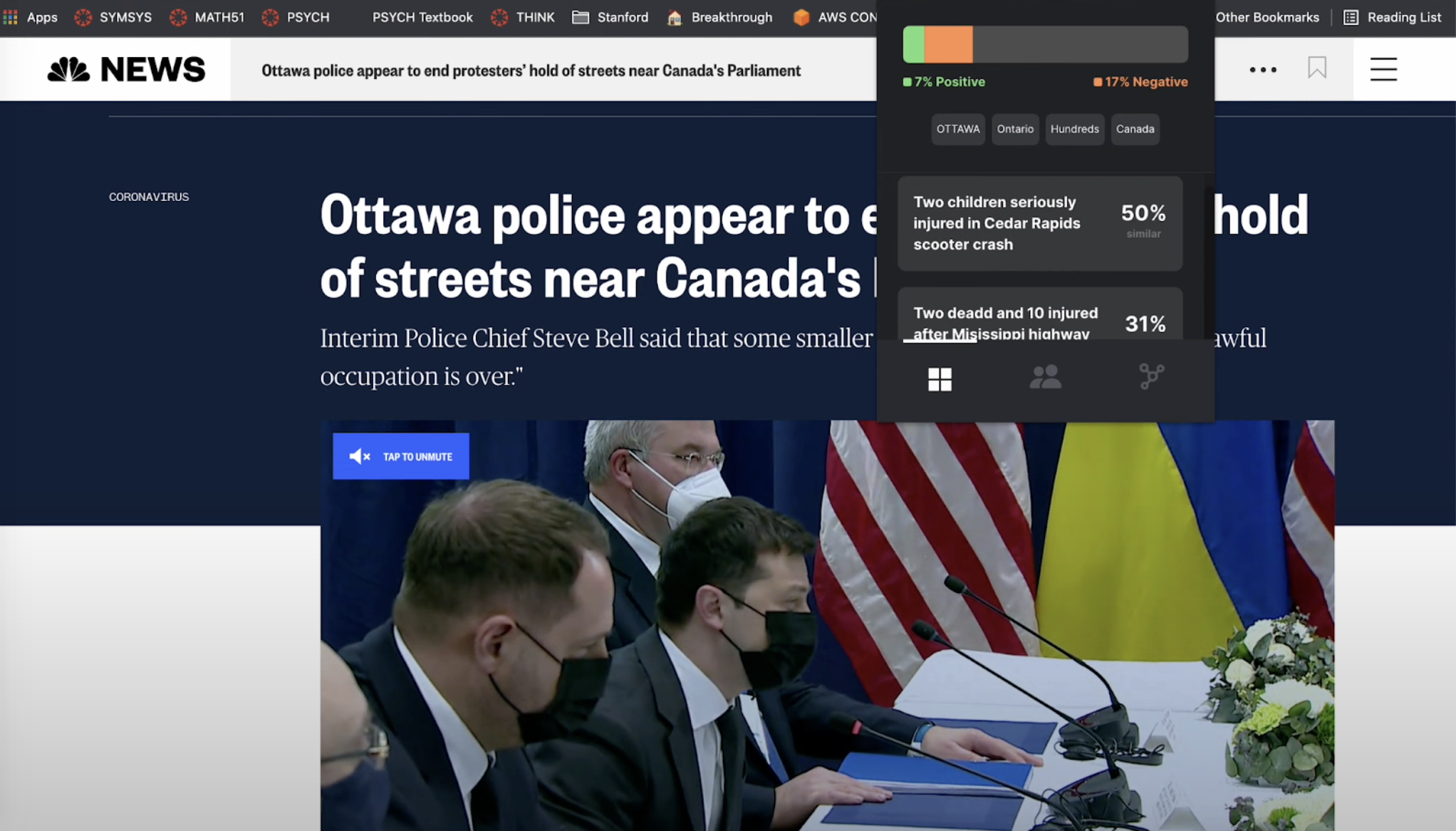
The starting screen where you can invoke the extension and see high-level sentiment around the topic you're interested in.
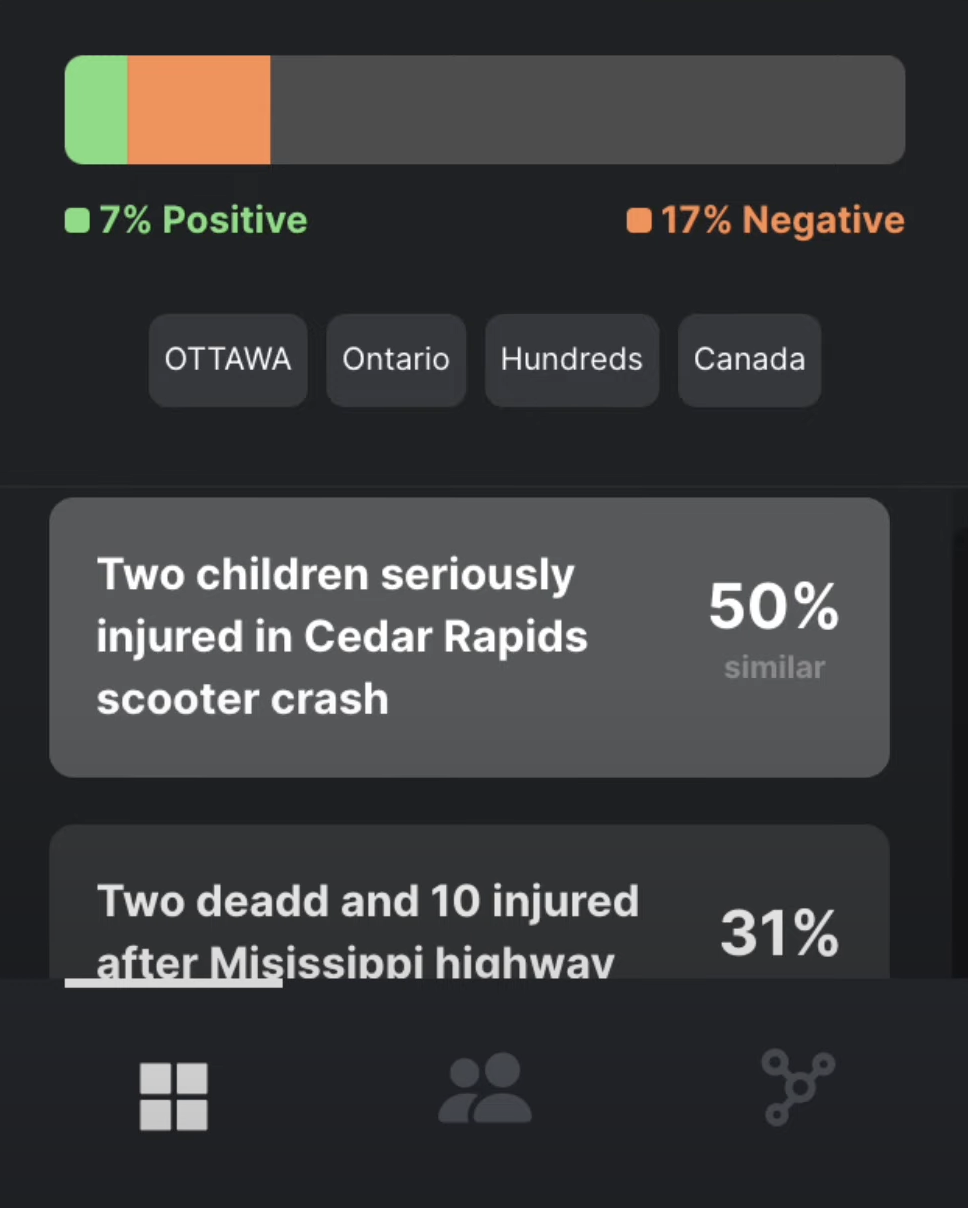
Extension view from article page.
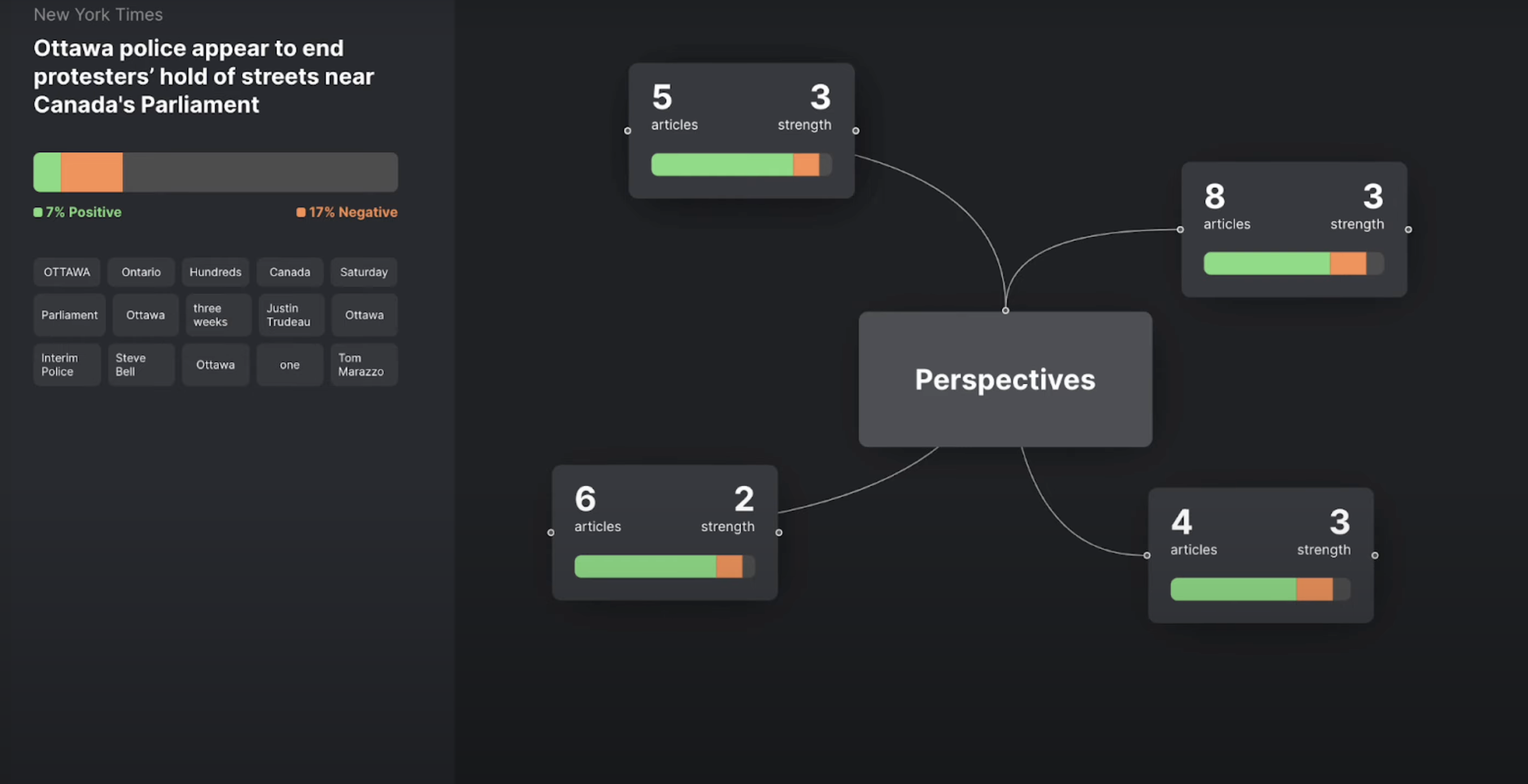
More detailed view of different cluster/perspectives on the topic you were reading.
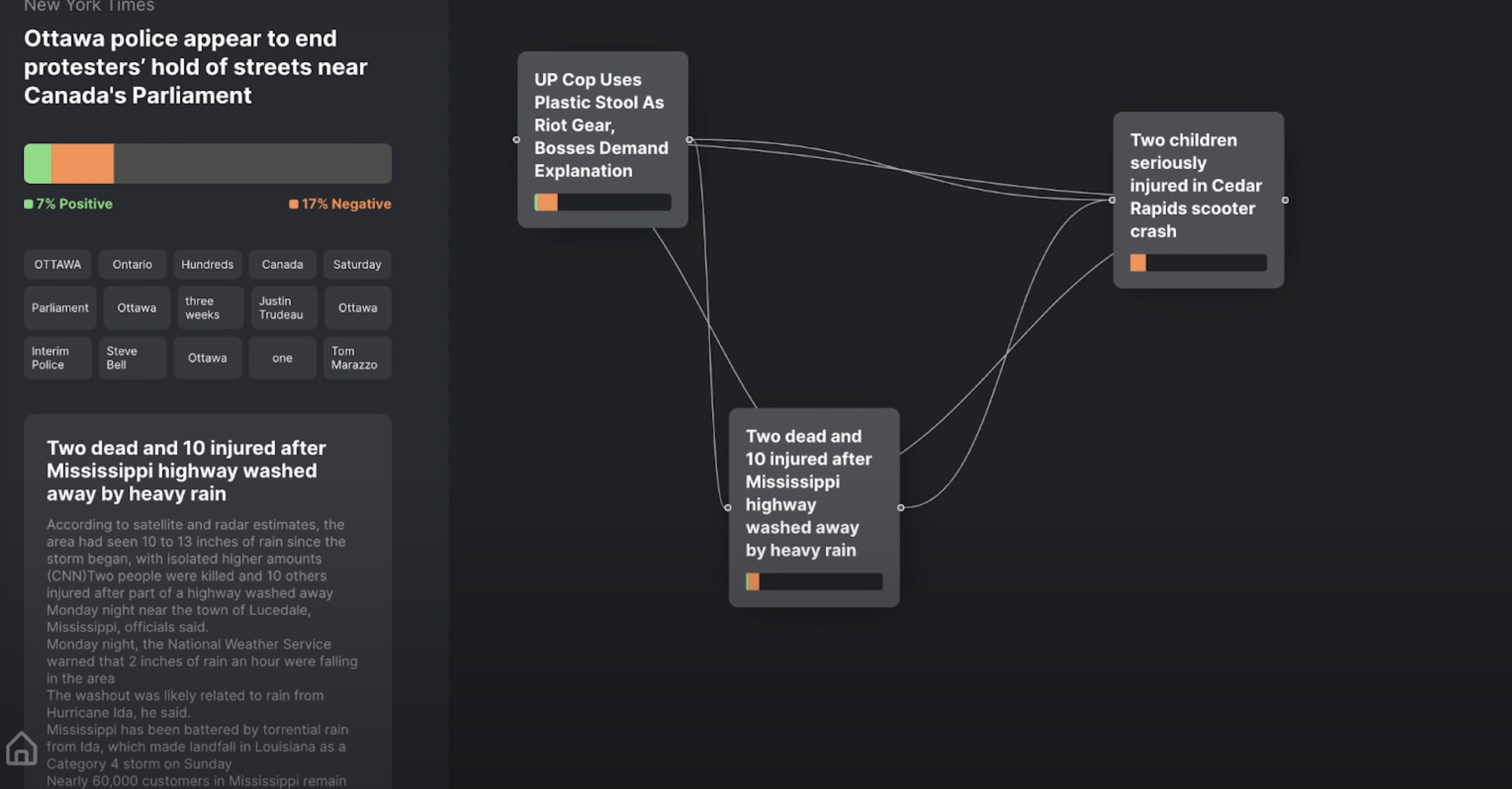
Clicking into a cluster/perspective and seeing the news articles within that perspective.
How we built it
Development was broken into three components: scraping, NLP processing + API, and chrome extension development. Scraping involved using Selenium, BS4, DiffBot (API that scrapes text from websites and sanitizes), and Google Cloud Platform’s Custom Search API to extract similar documents from the web. NLP processing involved using NLTK, KProtoype clustering algorithm. Chrome extension was built with React, which talked to a Flask API. Flask server is hosted on an AWS EC2 instance.
Challenges we ran into
Scraping: Getting enough documents that match the original article was a challenge because of the rate limiting of the GCP API. NLP Processing: one challenge here was determining metrics for clustering a batch of documents. Sentiment scores + top keywords were used, but more robust metrics could have been developed for more accurate clusters. Chrome extension: Figuring out the layout of the graph representing clusters was difficult, as the library used required an unusual way of stating coordinates and edge links. Flask API: One challenge in the API construction was figuring out relative imports.
Accomplishments that we’re proud of
Scraping: Recursively discovering similar documents based on repeatedly searching up headline of an original article. NLP Processing: Able to quickly get a similarity matrix for a set of documents.
What we learned
Learned a lot about data wrangling and shaping for front-end and backend scraping.
What’s next for WorldView
Explore possibility of letting those unable to bypass paywalls of various publishers to still get insights on perspectives.